 Arctic SDI catalogue
Arctic SDI catalogue
RI_623
Type of resources
Available actions
Topics
Keywords
Contact for the resource
Provided by
Formats
Representation types
Update frequencies
status
Scale
-

Each pixel value corresponds to the mean historical “Best-quality” Max-NDVI value for a given week, as calculated from the previous 20 years in the MODIS historical record (i.e. does not include data from the current year). These data are also often referred to as “weekly baselines” or “weekly normals”.
-

Dry spell periods are defined as the number of days (April 1 – October 31) where daily precipitation is less than 0.5 mm. This is not an accumulation of precipitation, simply a count of days. Dry spell products are only generated during the Growing Season, April 1 through October 31.
-

Last Spring Frost (0 °C) is defined as the average day, during the first half of the year, of the last occurrence of a minimum temperature at or below 0 °C. These values are calculated across Canada in 10x10 km cells.
-

The Moisture Anomaly Index (Palmer-Z) is an estimate of the moisture difference from normal (a 30-year mean). It attempts to express conditions for the current month regardless of what may have occurred before the month in question.
-

Monthly mean temperature from Bedford Institute of Oceanography North Atlantic Model (BNAM) results were averaged over 1990 to 2015 period to create monthly mean climatology for the Northwest Atlantic Ocean, which can be considered as a representation of the climatological state of the Northwest Atlantic Ocean. The BNAM model is eddy-resolving, NEMO-based ice-ocean coupled North Atlantic Ocean model developed at the Bedford Institute of Oceanography (BIO) to support DFO monitoring programs. The data available here is monthly climatology for eight selected depths (surface, 110 m, 156 m, 222 m, 318 m, 541 m, 1062 m, bottom) in 1/12 degree spatial resolution. The data for each month from 1990 until present for the entire model domain ( 8°–75°N latitude and 100°W–30°E longitude) and various depths is available upon request. The 1990-2017 model hindcast result is compared with observational data from surface drifter and satellite altimetry. The model demonstrates good skill in simulating surface currents, winter convection events in the Labrador Sea, and the Atlantic Meridional Overturning Circulation as observed at 26.5°N and 41°N. Model results have been used to interpret changes in the Labrador Current and observed warming events on the Scotian Shelf, and are reported through the annual AZMP Canadian Science Advisory Secretariat Process. When using data please cite following: Wang, Z., Lu, Y., Greenan, B., Brickman, D., and DeTracey, B., 2018. BNAM: An eddy resolving North Atlantic Ocean model to support ocean monitoring. Can. Tech. Rep. Hydrogr. Ocean. Sci. 327: vii + 18p
-

30-year Average Number of Days with Minimum Daily Temperature below -30 °C is defined as the count of climate days during the month where the minimum daily temperature was below -30 °C. These values are calculated across Canada in 10x10 km cells.
-
The impact of climatic variability on the environment is of great importance to the agricultural sector in Canada. Monitoring the impacts on water supplies, soil degradation and agricultural production is essential to the preparedness of the region in dealing with possible drought and other agroclimate risks. Derived normal climate data represent 30-year averages (1961-1990, 1971-2000, 1981-2010, 1991-2020) of climate conditions observed at a particular location. The derived normal climate data represents 30-year averages or “normals” for precipitation, temperature, growing degree days, crop heat units, frost, and dry spells. These normal trends are key to understanding agroclimate risks in Canada. These normal can be used as a baseline to compare against current conditions, and are particularly useful for monitoring drought risk.
-

A history of nearshore benthic surveys of Bras d’Or Lake from 2005 – 2011 is presented. Early work utilized drop camera and fixed mount sidescan. The next phase was one of towfish development, where camera and sidescan were placed on one platform with transponder-based positioning. From 2009 to 2011 the new towfish was used to ground truth an echosounder. The surveys were performed primarily in the northern half of the lake; from 10 m depth right into the shallows at less than 1 m. Different shorelines could be distinguished from others based upon the relative proportions of substrate types and macrophyte canopy. The vast majority of macrophytes occurred within the first 3 m of depth. This zone was dominated by a thin but consistent cover of eelgrass (Zostera marina L.) on almost all shores with a current or wave regime conducive to the growth of this plant. However, the eelgrass beds were frequently in poor shape and the negative impacts of commonly occurring water column turbidity, siltation, or possible localized eutrophication, are suspected. All survey data were placed into a Geographic Information System, and this document is a guide to that package. The Geographic Information System could be used to answer management questions such as the placement and character of habitat compensation projects, the selection of nearshore protected areas or as a baseline to determine long term changes. Vandermeulen, H. 2016. Video-sidescan and echosounder surveys of nearshore Bras d’Or Lake. Can. Tech. Rep. Fish. Aquat. Sci. 3183: viii + 39 p. Cite this data as: Vandermeulen H. Bay Scale Assessment of Nearshore Habitat Bras d'Or Lake. Published May 2022. Coastal Ecosystems Science Division, Fisheries and Oceans Canada, Dartmouth, N.S.
-
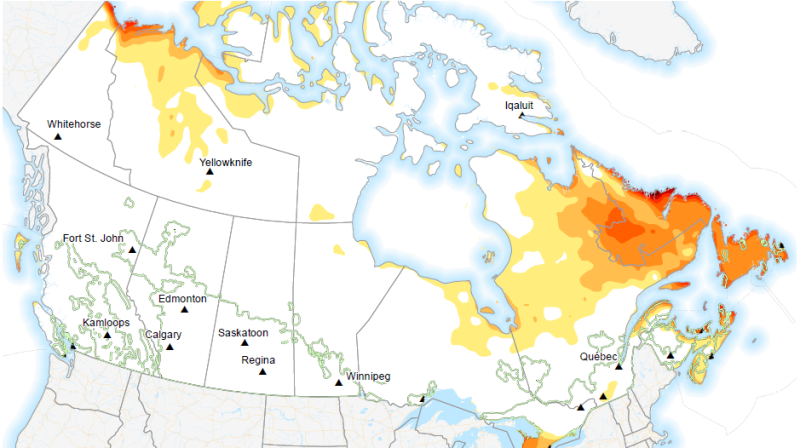
Winds can significantly influence crop growth and yield mainly due to mechanical damage of plant vegetative and reproductive organs, an imbalance of plant-soil-atmosphere water relationships such as evapotranspiration, and pest and disease distributions in agricultural fields. The maximum wind speed and the number of strong wind days over the forecast period represent short term and extended strong wind events respectively. Agriculture is an important primary production sector in Canada. Agricultural production, profitability, sustainability and food security depend on many agrometeorological factors. Extreme weather events in Canada, such as drought, floods, heat waves, frosts and high intensity storms, have the ability to significantly impact field crop production. Agriculture and Agri-Food Canada (AAFC) and Environment and Climate Change Canada (ECCC) have together developed a suite of extreme agrometeorological indices based on four main categories of weather factors: temperature, precipitation, heat, and wind. The extreme weather indices are intended as short-term prediction tools and generated using ECCC’s medium range forecasts to create a weekly index product on a daily basis.
-

Each pixel value corresponds to the quality control, cloud cover and snow fraction value for each pixel in the Best-Quality Max-NDVI product.